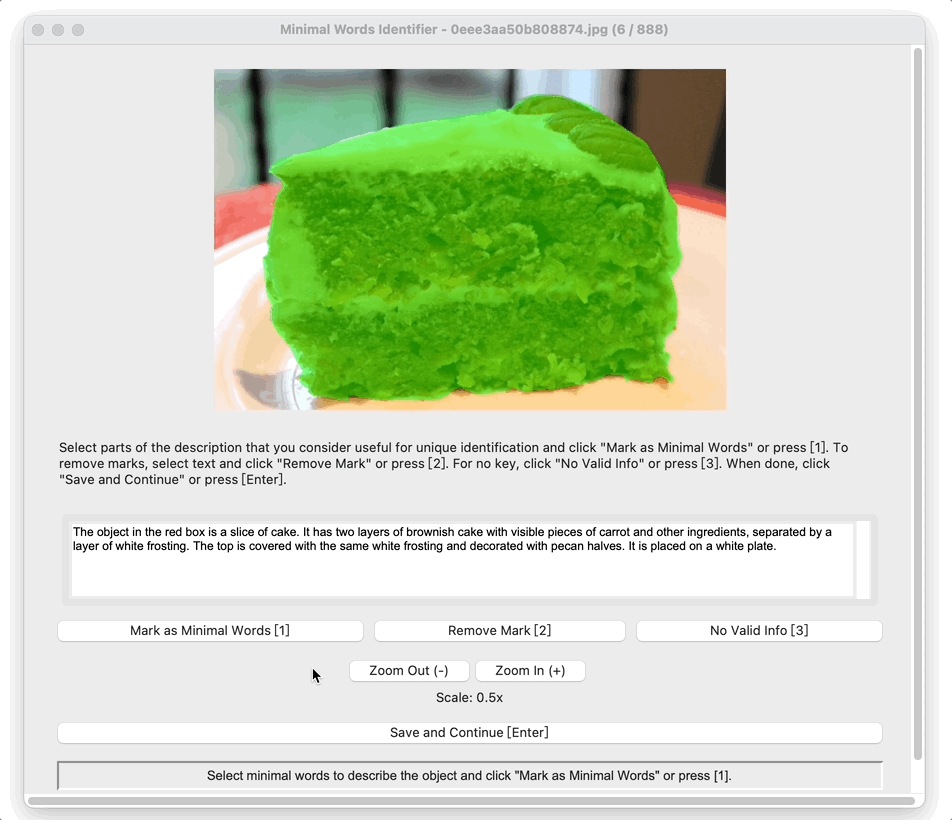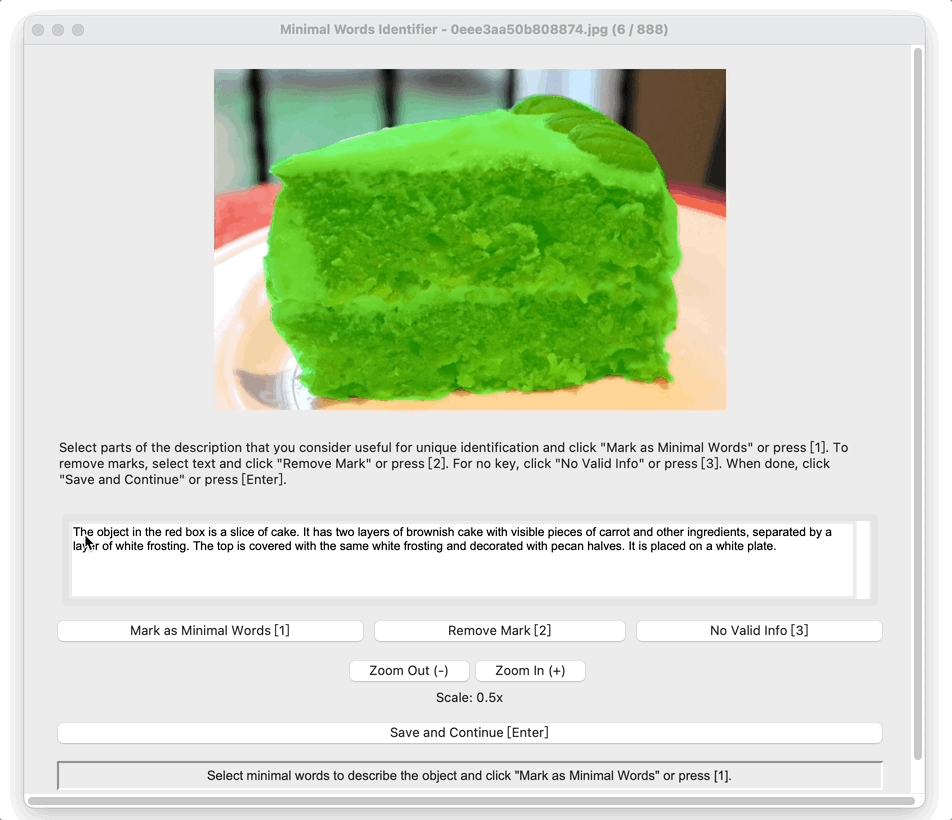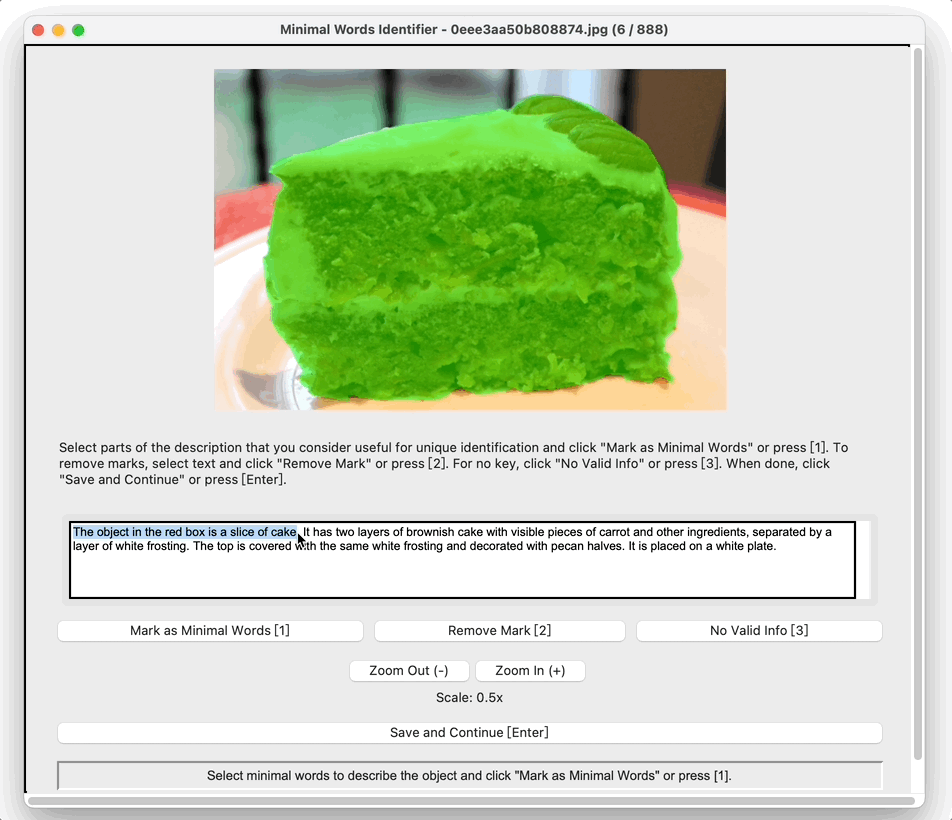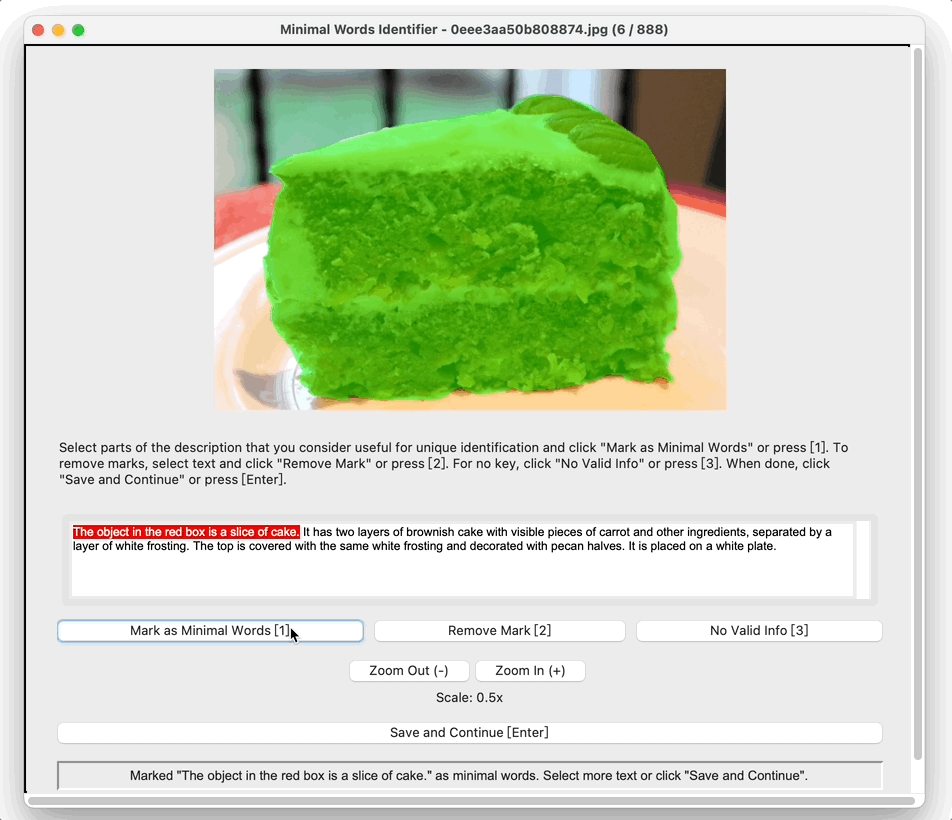
Misalignment to Human Pragmatic Preferences
[Synthetic Data]
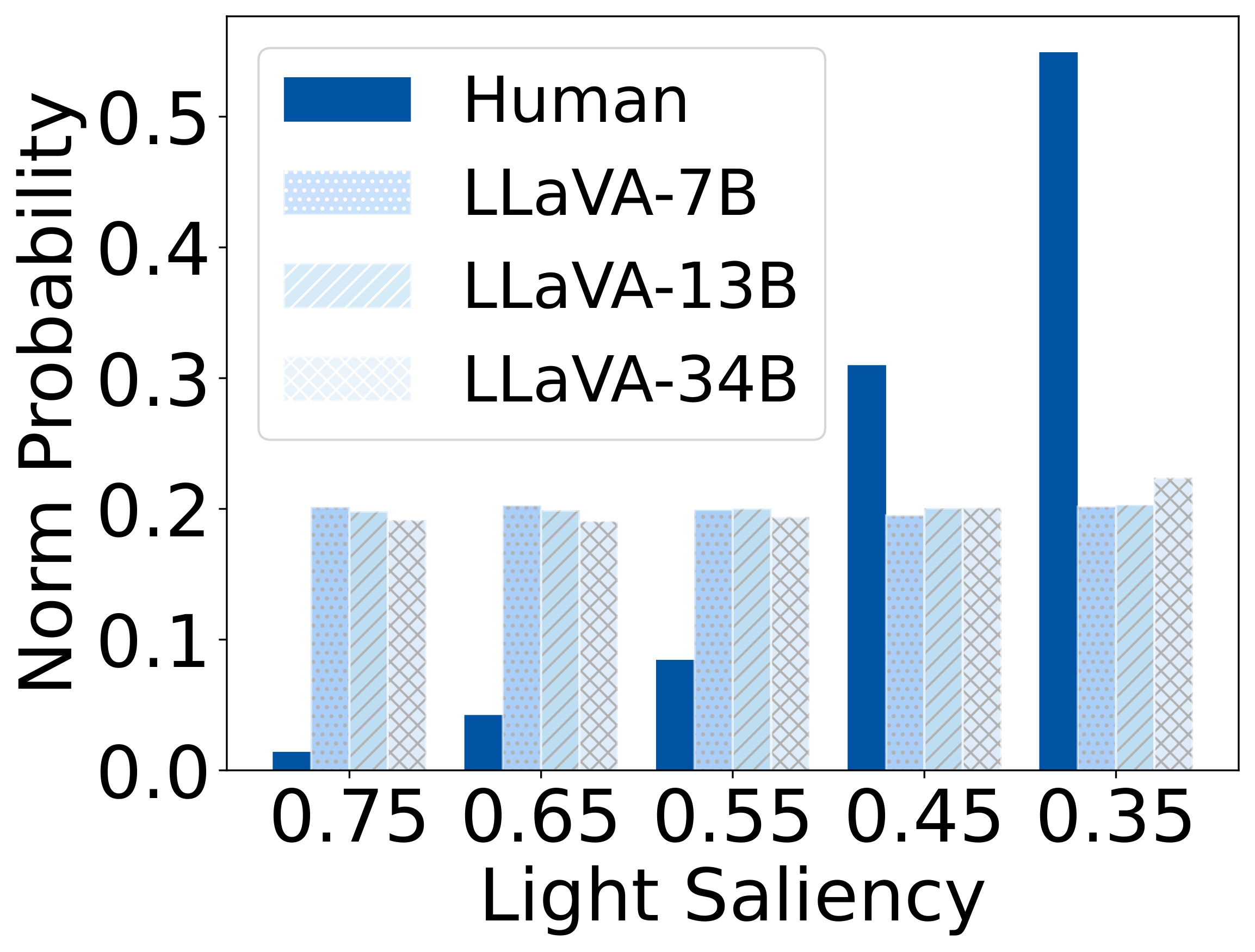
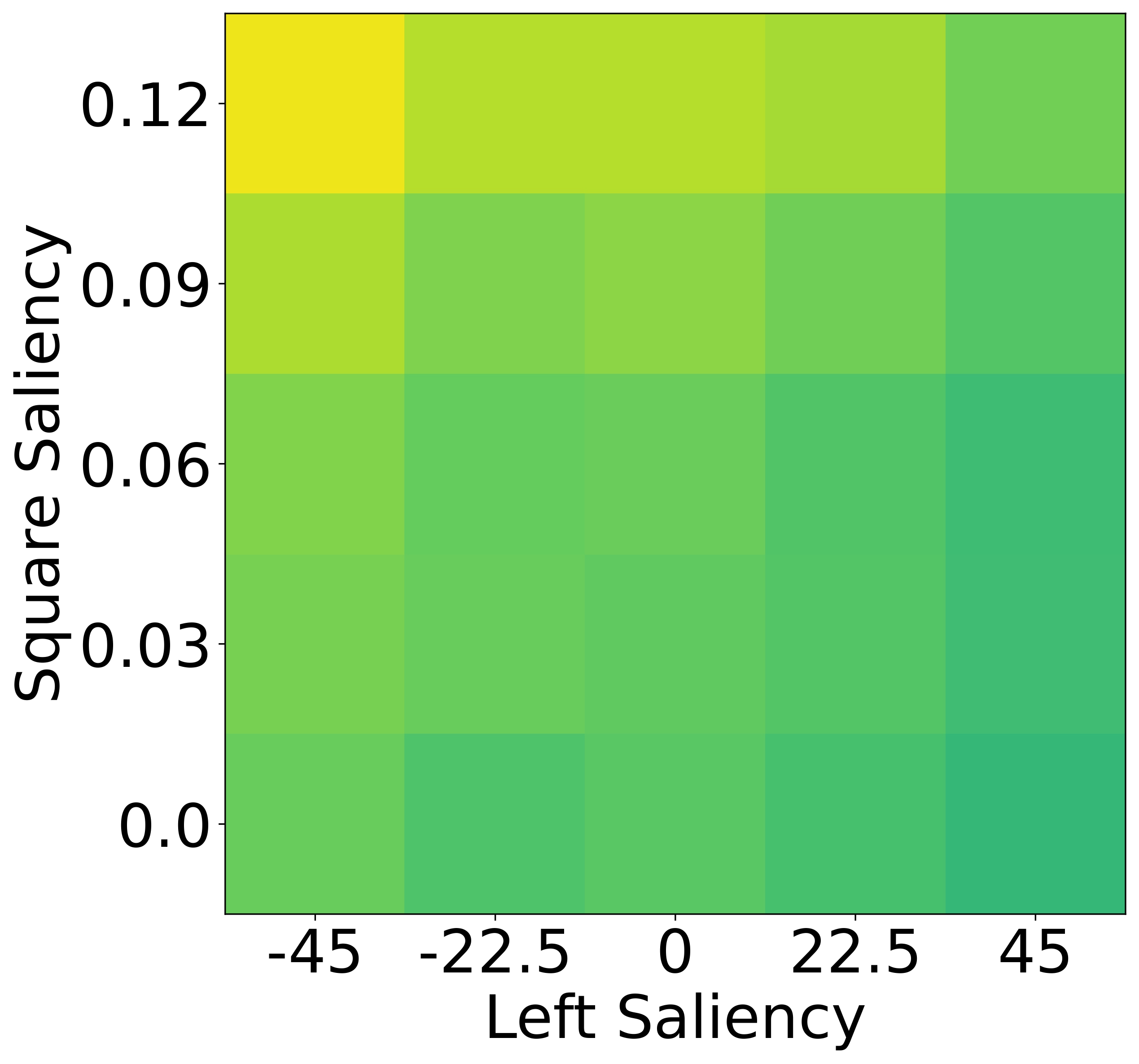
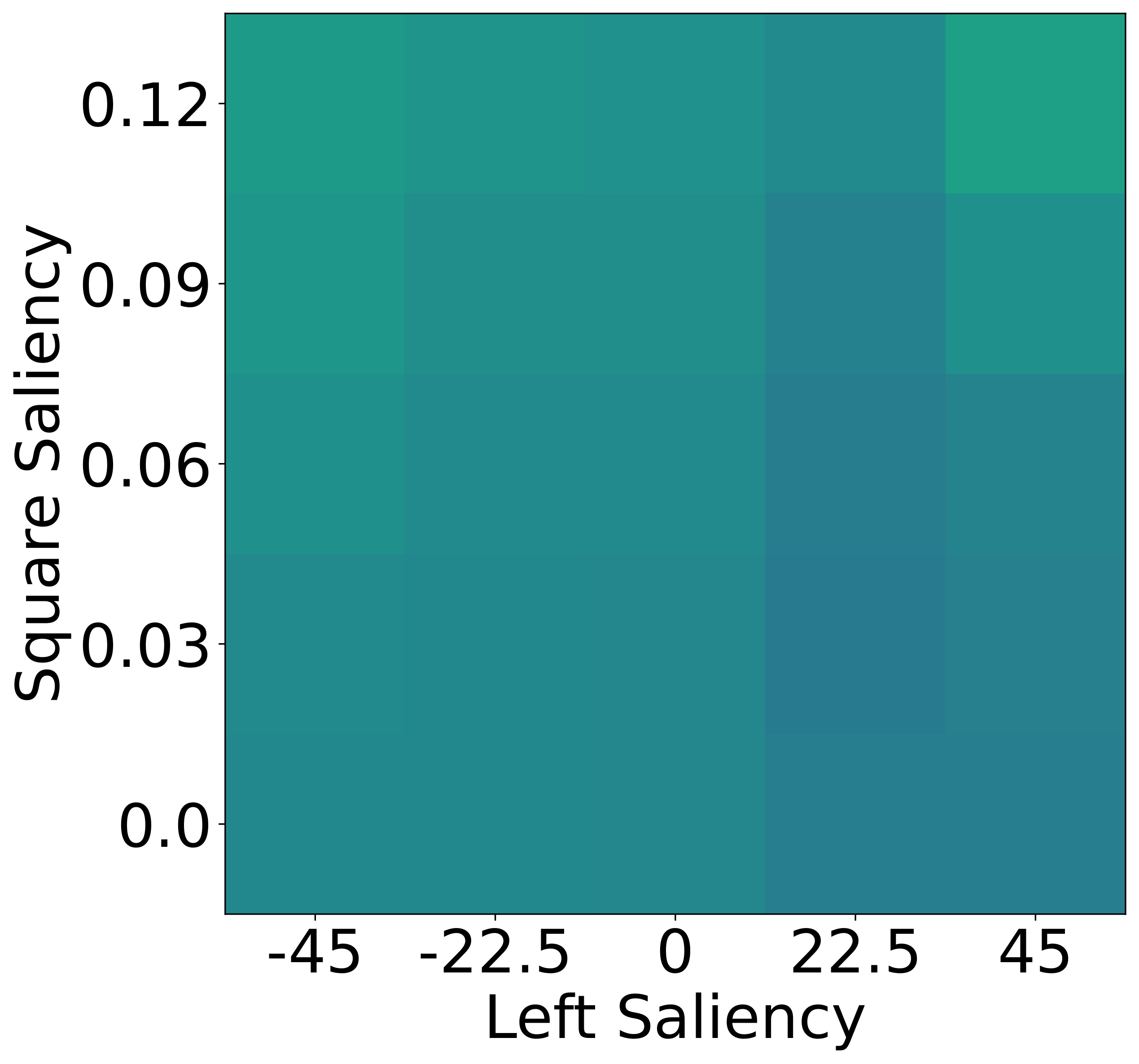
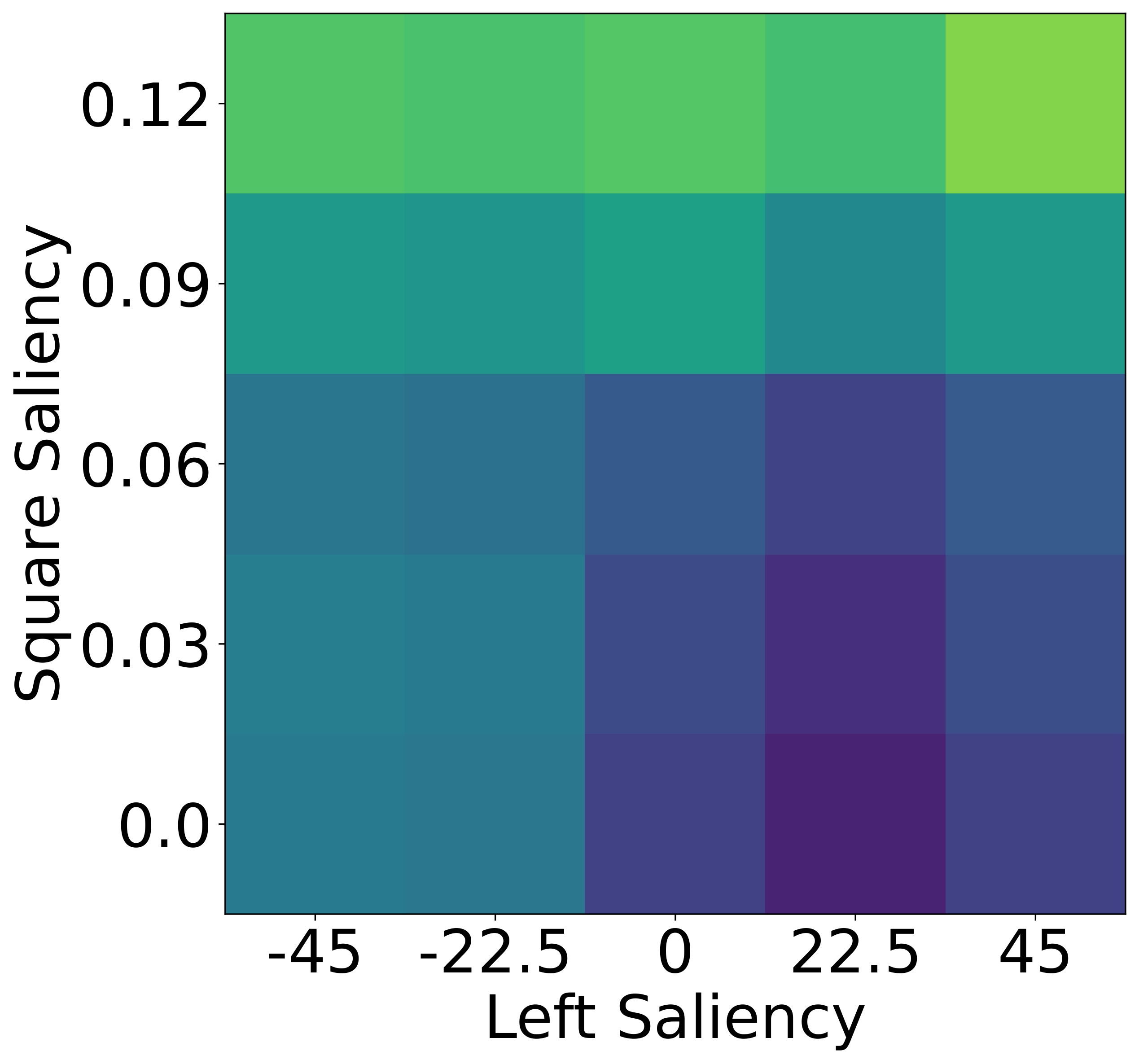
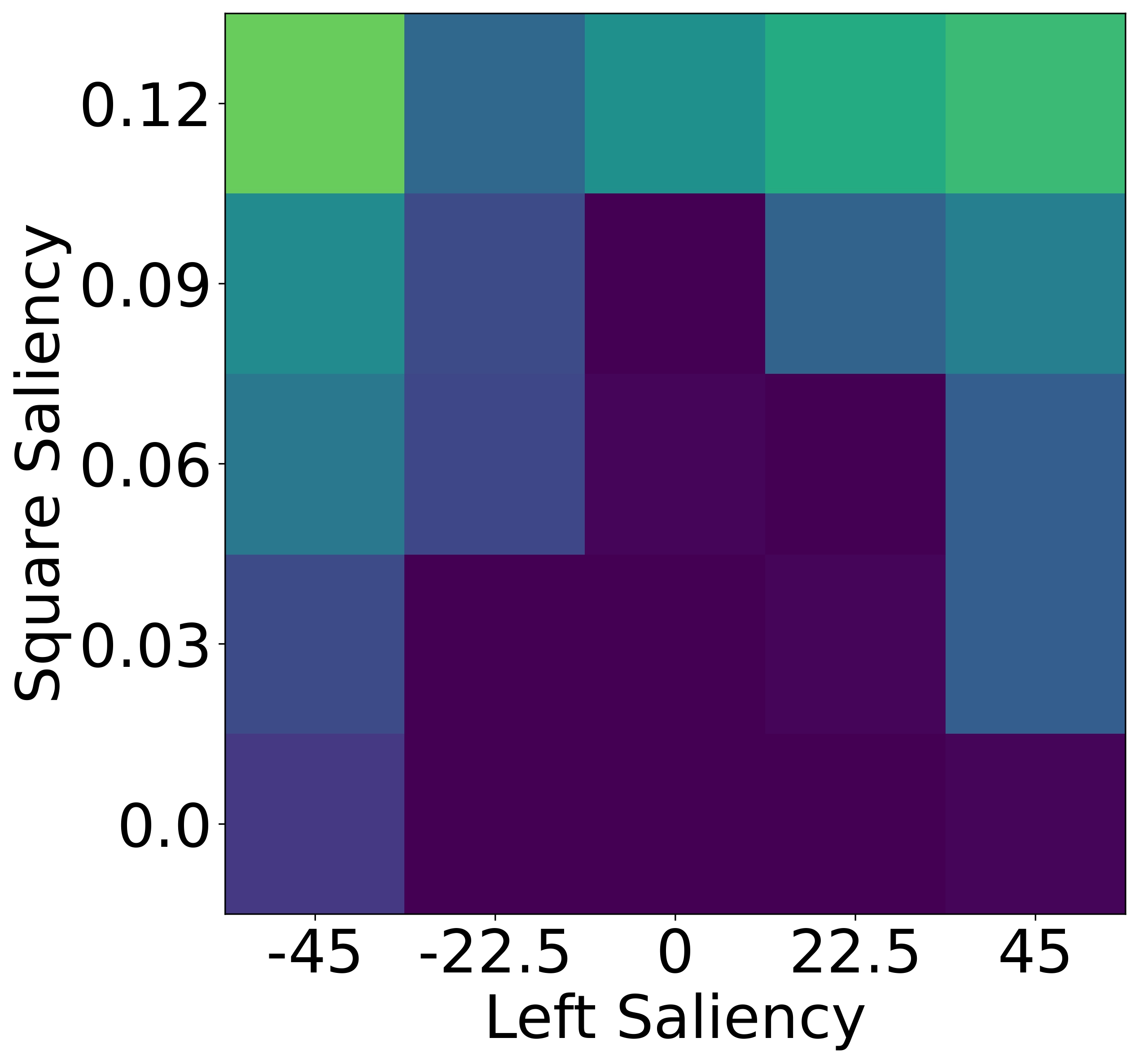
While humans heavily rely on spatial cues in referring expressions, VLMs often favor
combinations of visual attributes such as shape and color. This divergence reveals that VLMs
may not follow human pragmatic preferences when multiple minimal descriptions are available—violating Gricean
maxims of Relation and Quantity.
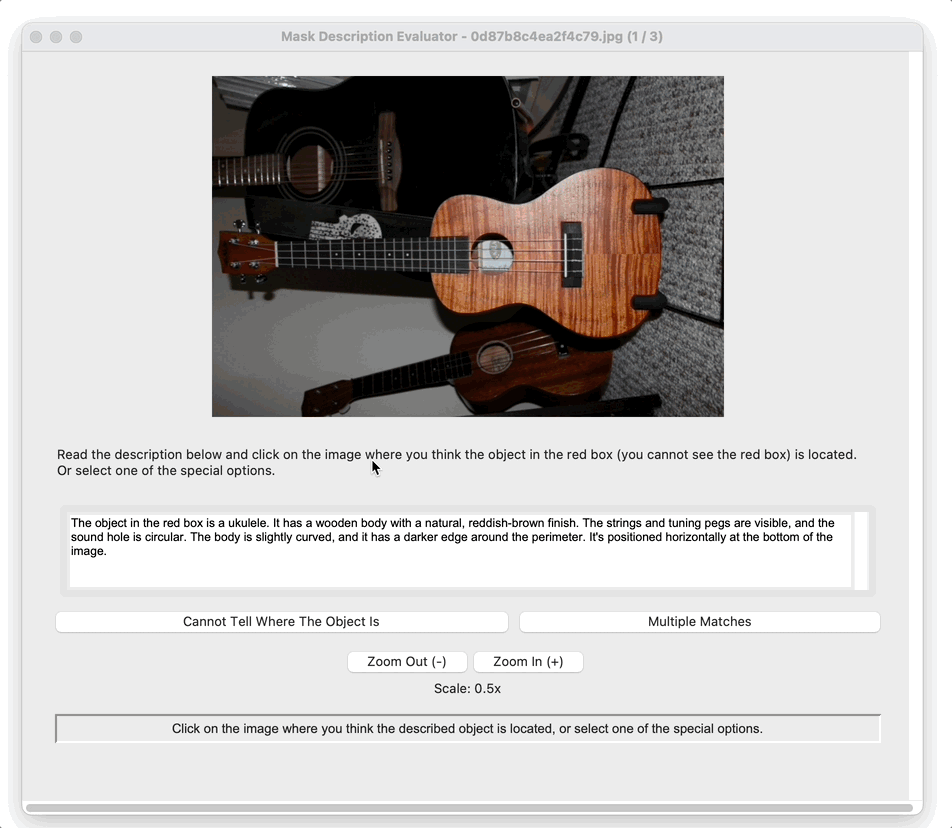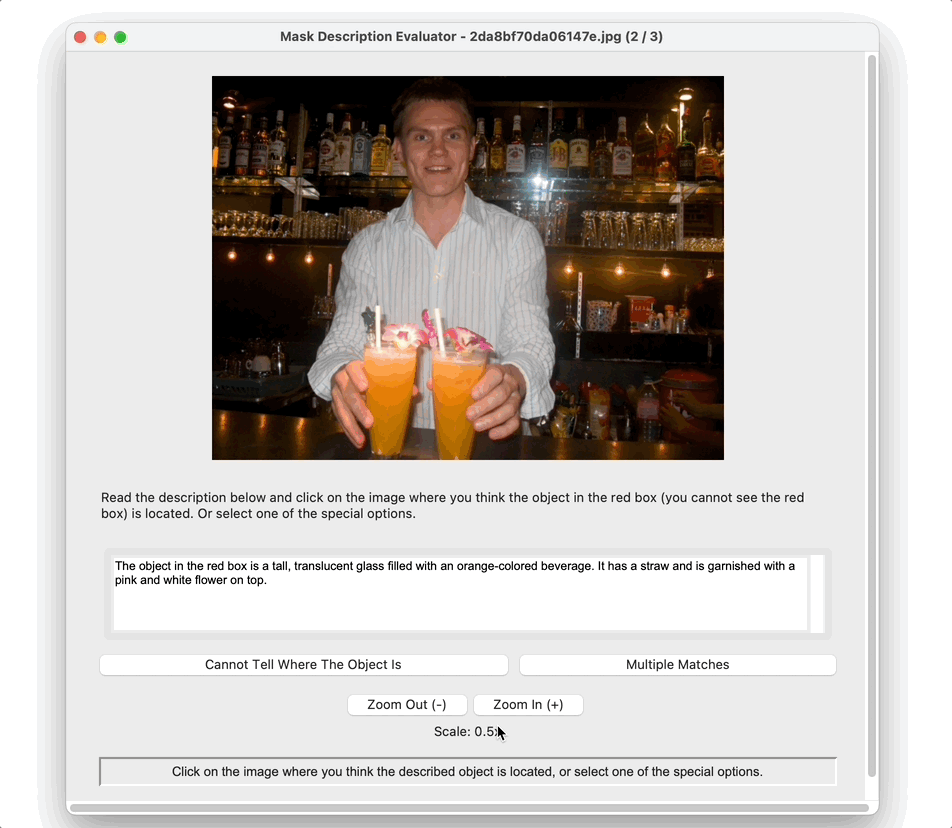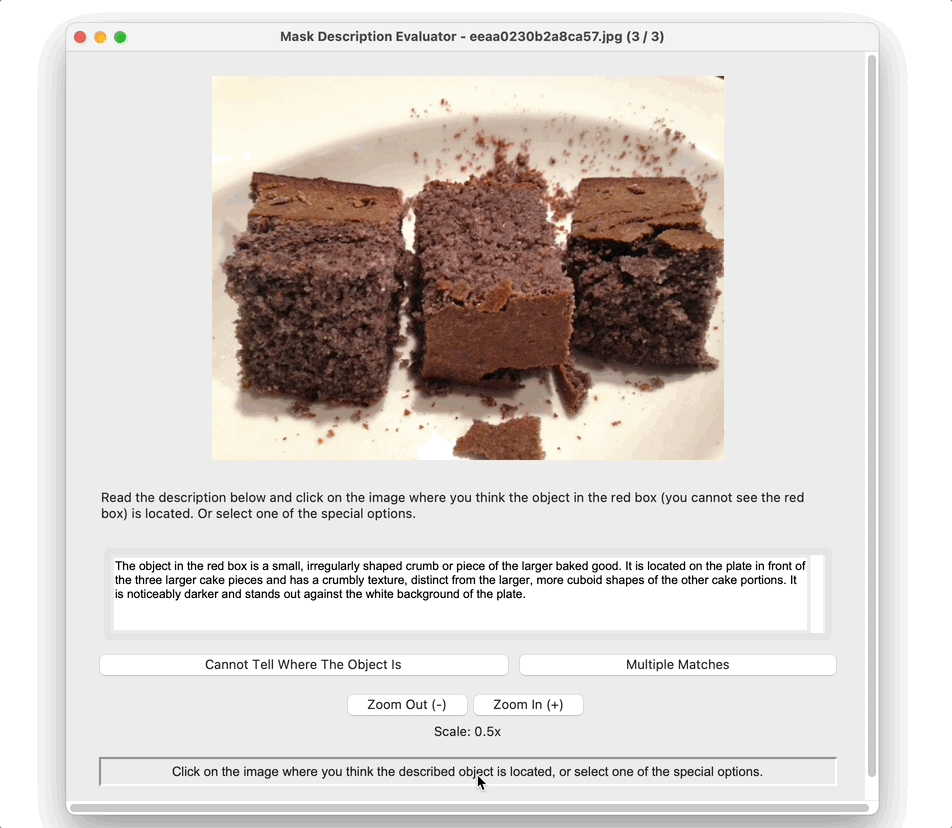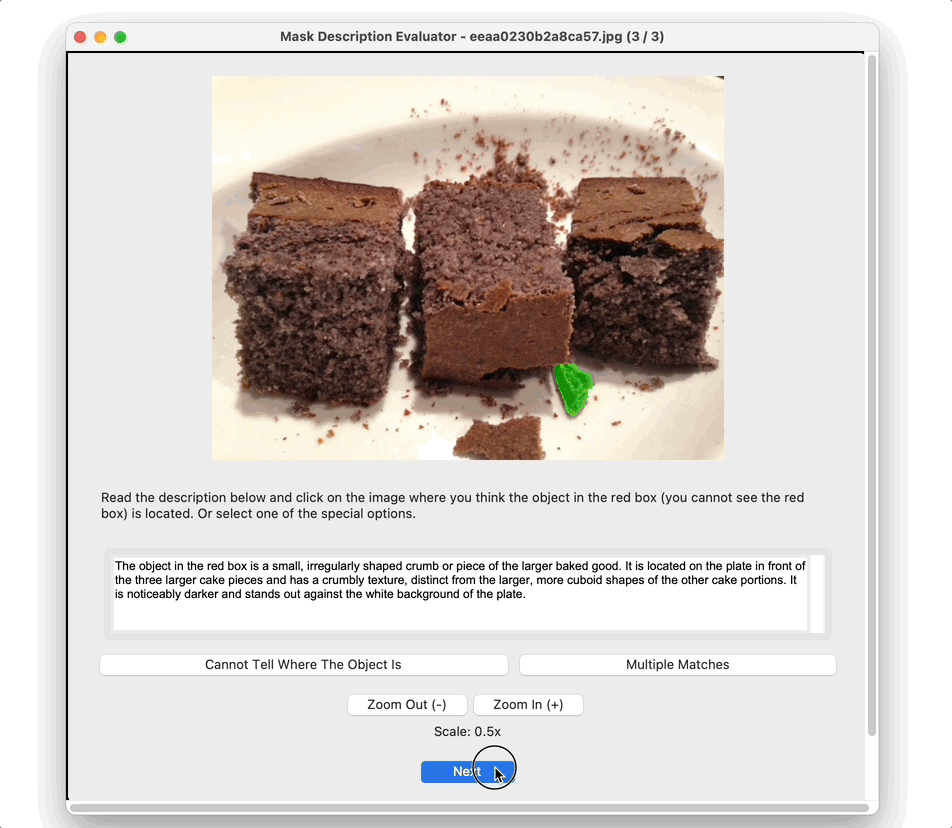
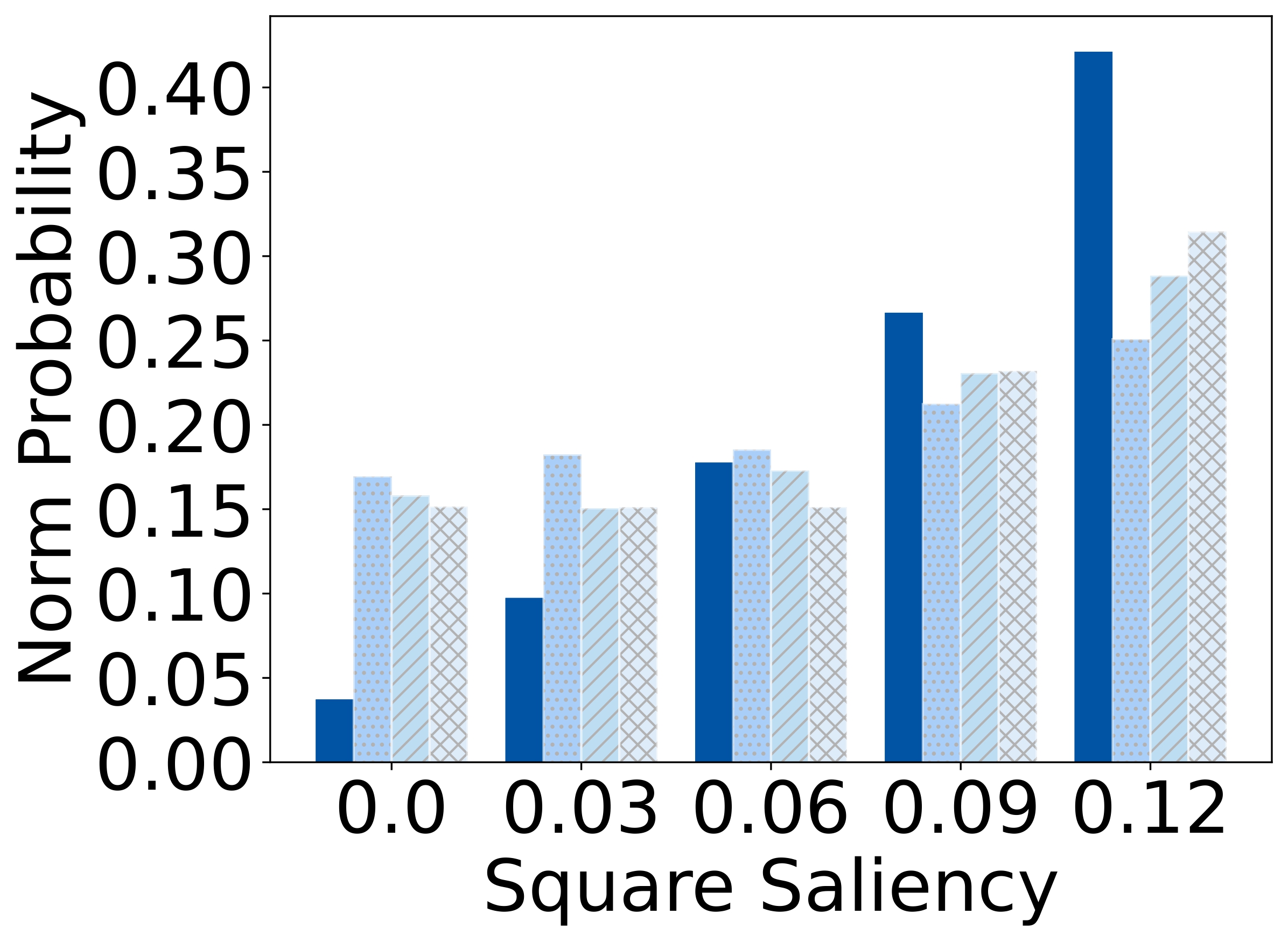
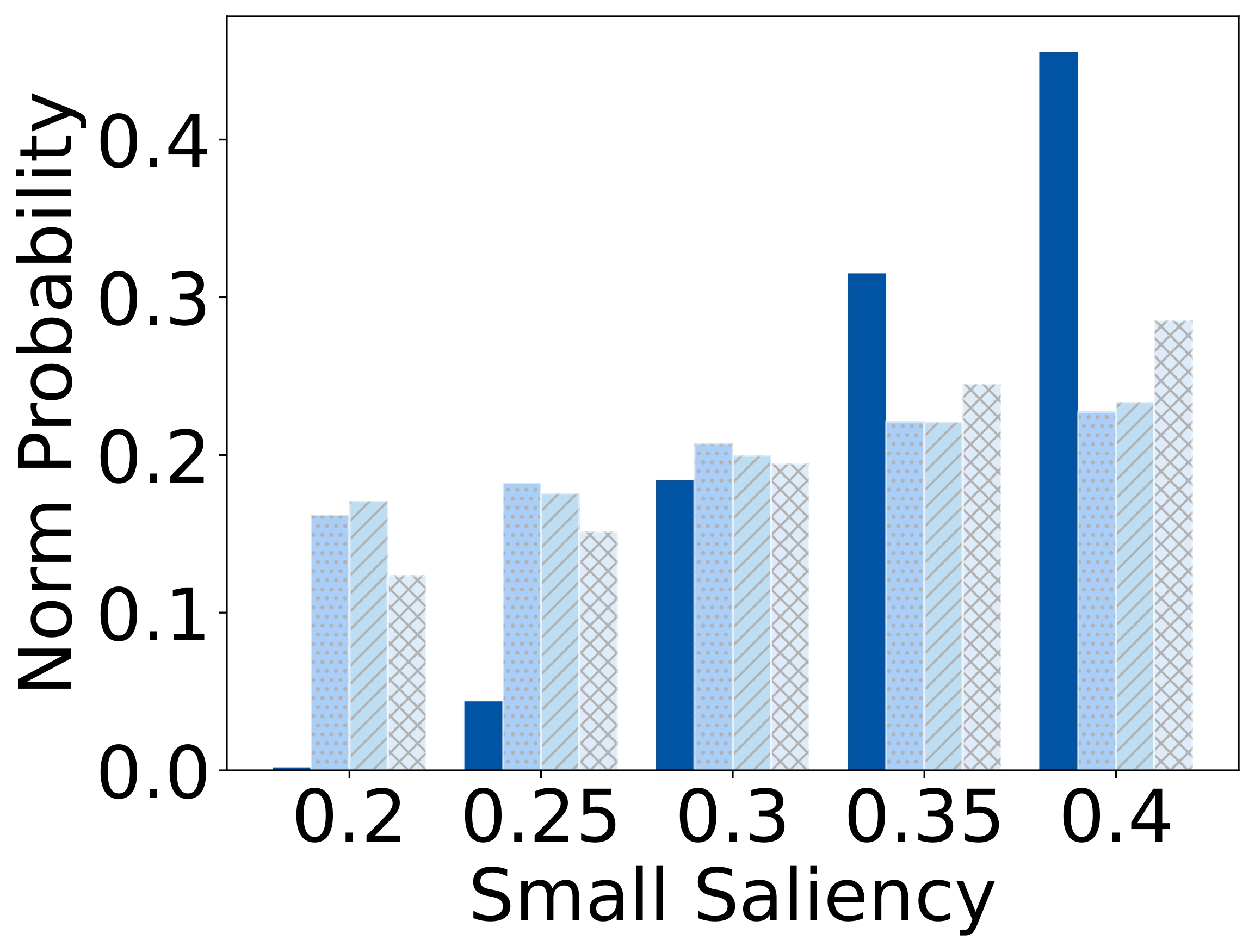
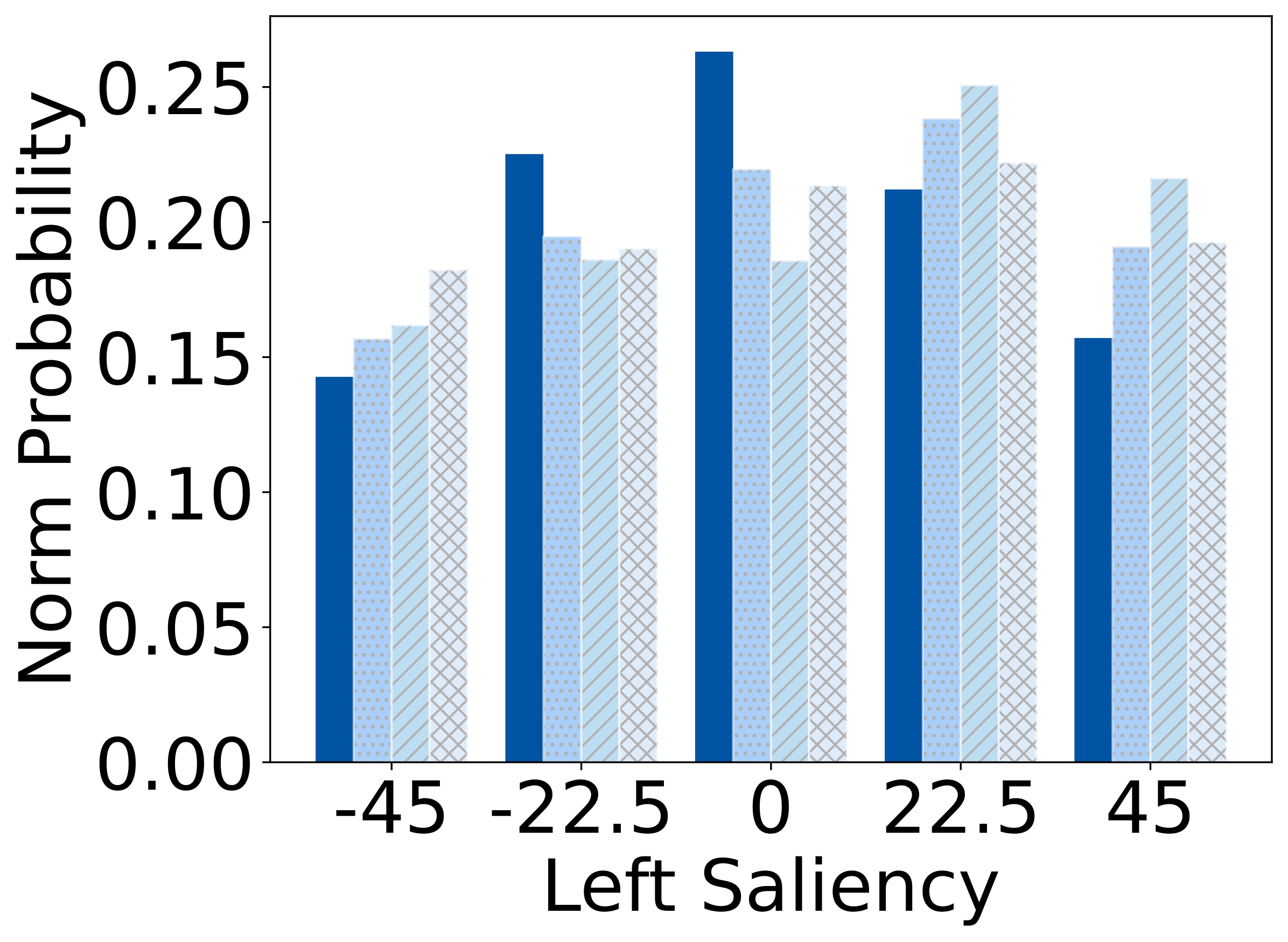
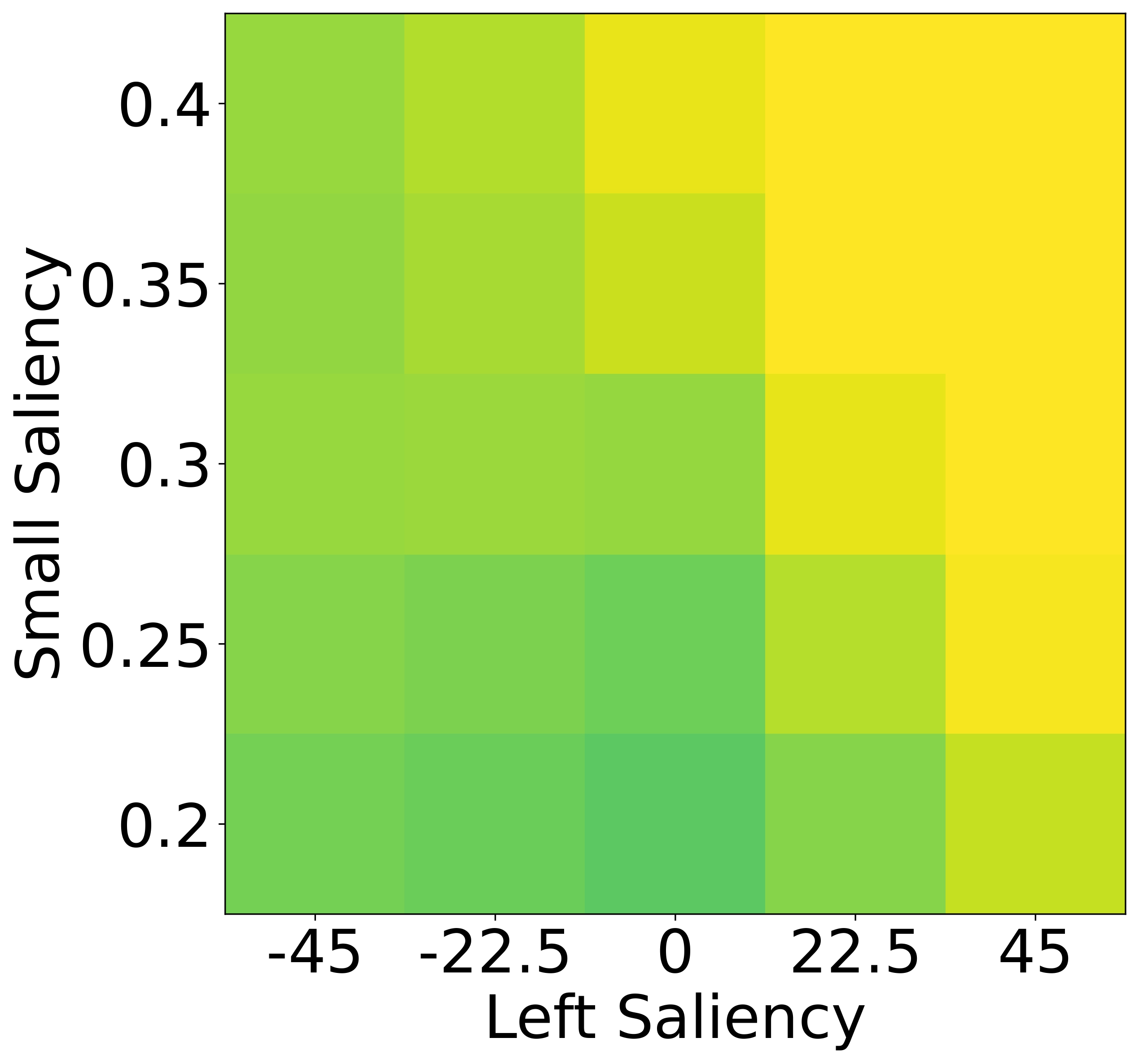
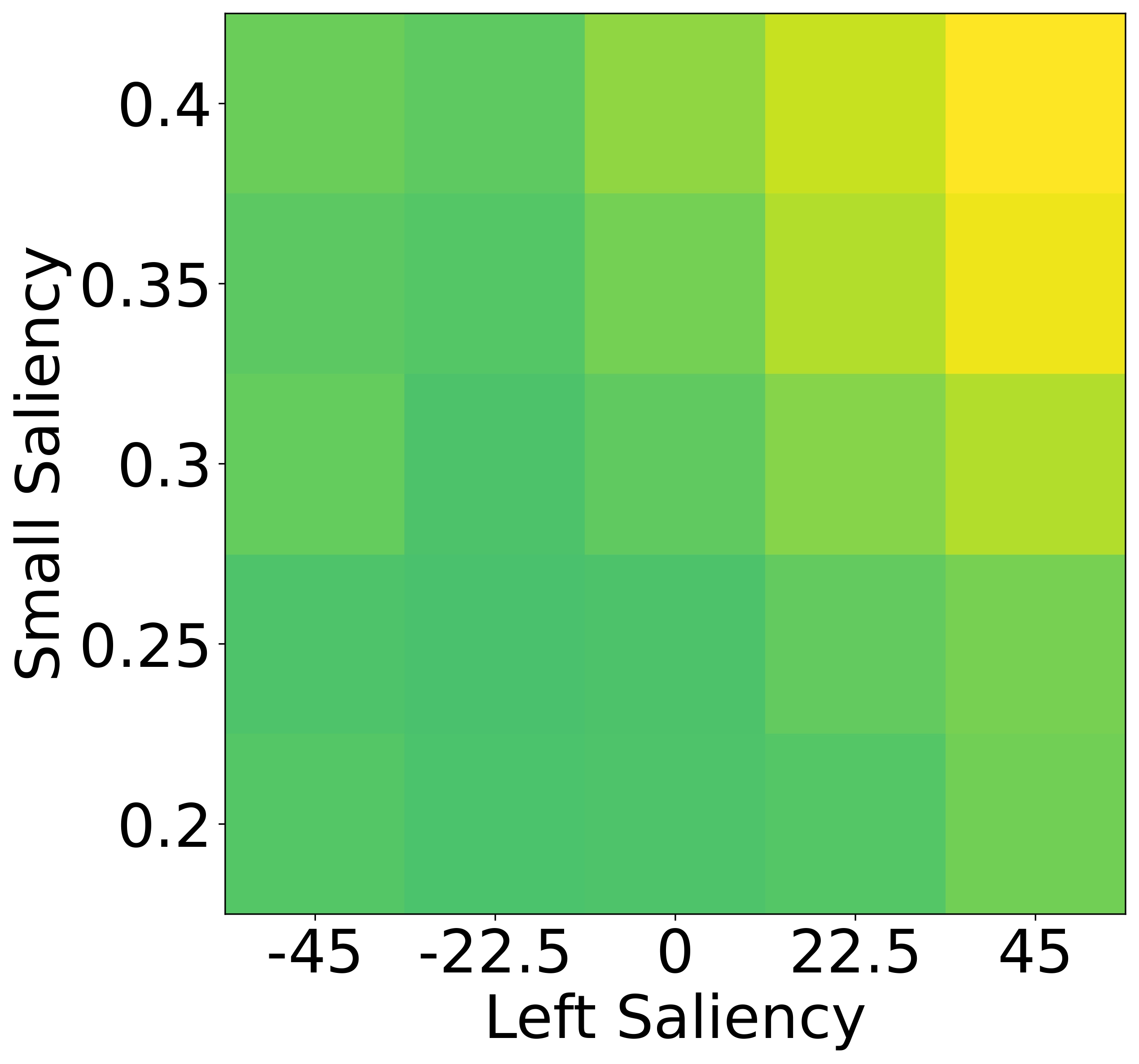
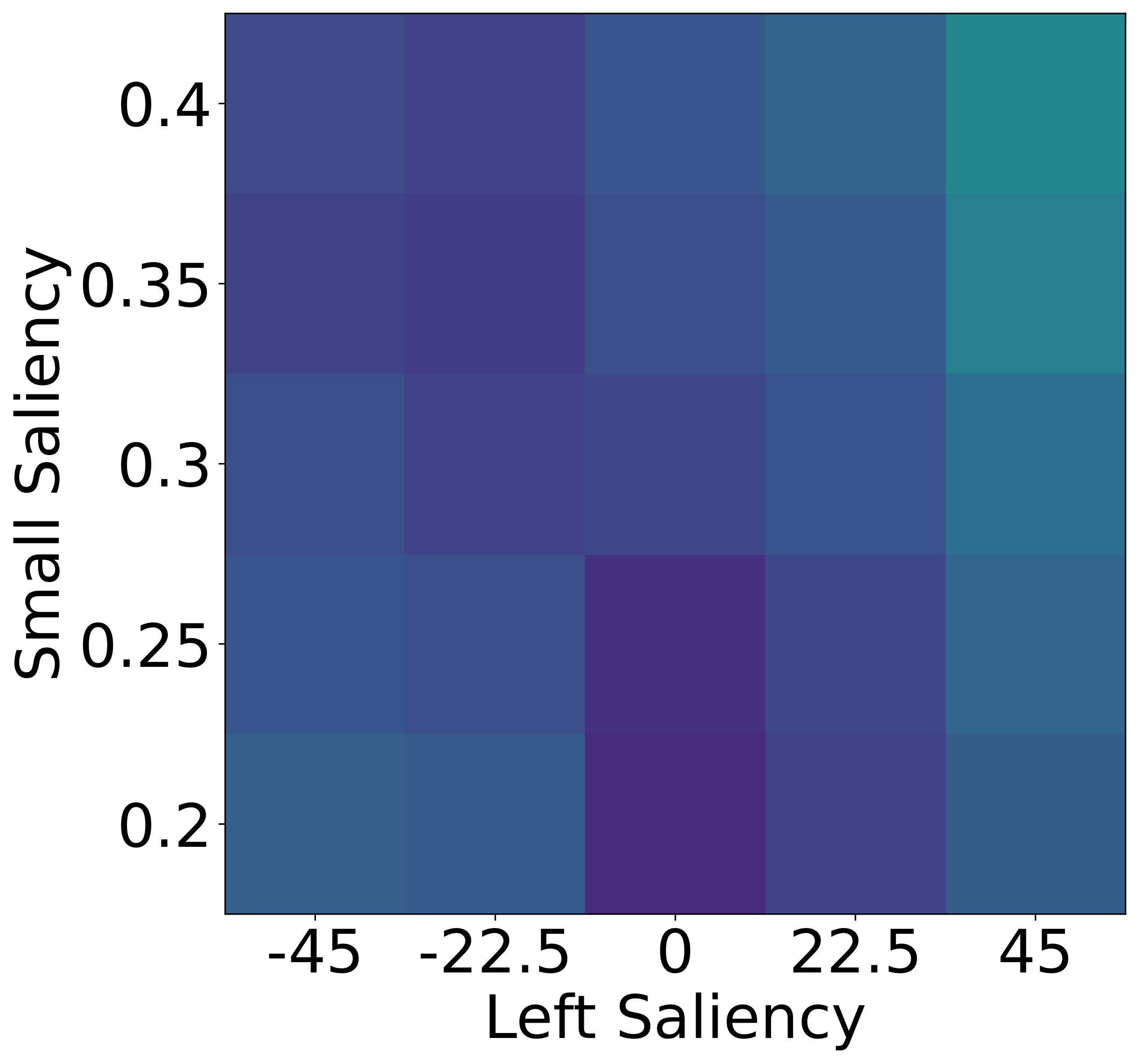
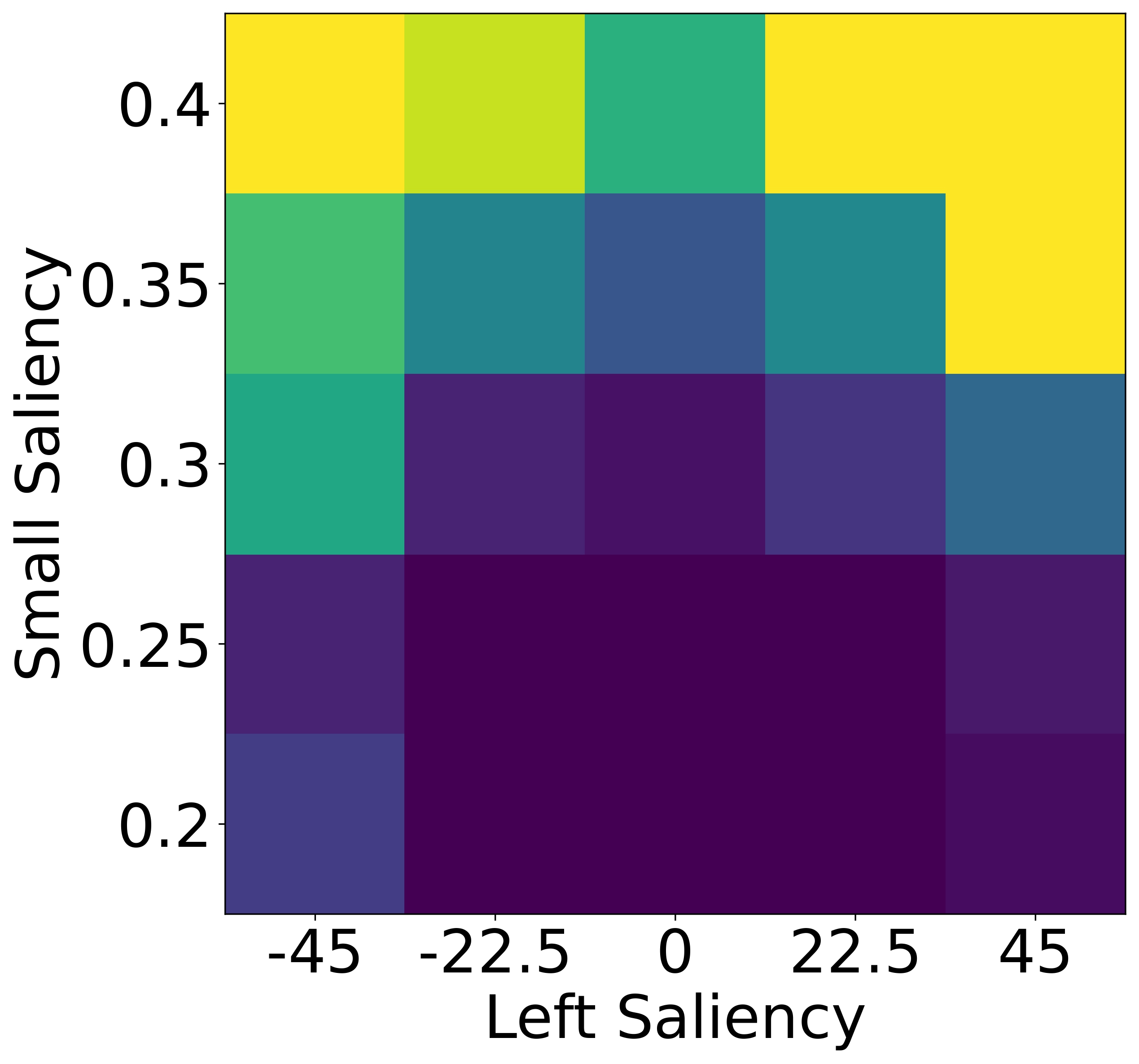
To isolate this effect, we design a synthetic dataset where each referent can be uniquely described using one
of four independent features: size, color, shape, or
position. Human responses are collected and compared with VLM likelihoods.
Results show that humans are highly sensitive to visual saliency and prefer the most contextually informative
cue. VLMs, in contrast, display flatter preference distributions and less discriminative usage of
features—highlighting a lack of pragmatic grounding.
Does Simple Prompting Fix Pragmatic Limitations?
Given the pragmatic failures of VLMs identified in our experiments, we further ask: Can these
shortcomings be mitigated through simple prompting techniques? To investigate this, we conducted
supplementary experiments on GPT-4o by evaluating two enhanced prompts that elicit better reasoning, building
on our brief prompt:
- Chain-of-Thought (CoT): This prompt directs a model to "think step by step," explicitly
articulating intermediate reasoning before committing to an answer.
- Gricean (Grn.): This prompt explicitly instructs the model to follow Gricean maxims of
cooperative communication, embedding a definition sourced from Wikipedia.
| Model |
Instr. |
BLEU-1 |
BLEU-4 |
ROUGE-1 |
ROUGE-L |
METEOR |
CIDEr |
SPICE |
BERT |
CLIP |
REC |
Human |
Irrel% |
| GPT-4o |
Dft. |
7.47 |
0.85 |
11.61 |
10.43 |
17.39 |
0.03 |
7.21 |
84.57 |
80.81 |
41.29 |
59.80 |
89.81 |
| Brf. |
25.30 |
5.78 |
28.76 |
27.36 |
19.02 |
8.17 |
15.31 |
88.11 |
76.58 |
40.08 |
51.72 |
52.75 |
| CoT |
19.98 |
4.02 |
23.42 |
21.84 |
18.15 |
10.15 |
13.36 |
86.83 |
77.59 |
46.67 |
65.59 |
65.71 |
| Grn. |
21.43 |
4.33 |
25.62 |
24.01 |
20.35 |
10.85 |
13.87 |
87.57 |
78.50 |
42.10 |
63.50 |
62.40 |
| Human |
Spk. |
66.18 |
22.58 |
70.15 |
66.45 |
48.28 |
112.04 |
42.35 |
93.89 |
71.60 |
64.56 |
92.20 |
9.15 |
| Wrt. |
- |
- |
- |
- |
- |
- |
- |
- |
70.43 |
63.69 |
89.29 |
7.29 |
Supplementary results for reasoning-oriented prompts of GPT-4o.
| Model |
Instr. |
Listener Compare |
Error Breakdown |
Class Breakdown |
Class Co-occurrence |
| Human |
REC |
Agree |
Wrong% |
Multi.% |
No-Mat% |
COCO |
No-COCO |
ΔAcc |
Coocc. |
No-Coocc. |
ΔAcc |
| GPT-4o |
Dft. |
59.80 |
41.29 |
62.00 |
11.98 |
24.04 |
4.18 |
63.31 |
56.28 |
-7.03 |
48.14 |
83.33 |
-35.19 |
| Brf. |
51.72 |
40.08 |
63.01 |
10.97 |
31.52 |
5.79 |
54.84 |
48.58 |
-6.26 |
37.36 |
80.69 |
-43.33 |
| CoT |
65.59 |
46.67 |
63.55 |
14.28 |
17.37 |
2.76 |
68.15 |
63.02 |
-5.13 |
54.98 |
86.99 |
-32.01 |
| Grn. |
63.50 |
42.10 |
60.52 |
14.08 |
19.80 |
2.62 |
65.05 |
61.94 |
-3.11 |
51.96 |
86.79 |
-34.83 |
| Human |
Spk. |
92.20 |
64.56 |
64.96 |
6.93 |
0.74 |
0.13 |
92.07 |
92.58 |
0.51 |
91.74 |
93.50 |
-1.76 |
| Wrt. |
89.29 |
63.69 |
63.69 |
7.68 |
2.36 |
0.67 |
89.52 |
89.07 |
-0.45 |
88.31 |
91.26 |
-2.95 |
Supplementary results breakdown for reasoning-oriented prompts of GPT-4o.
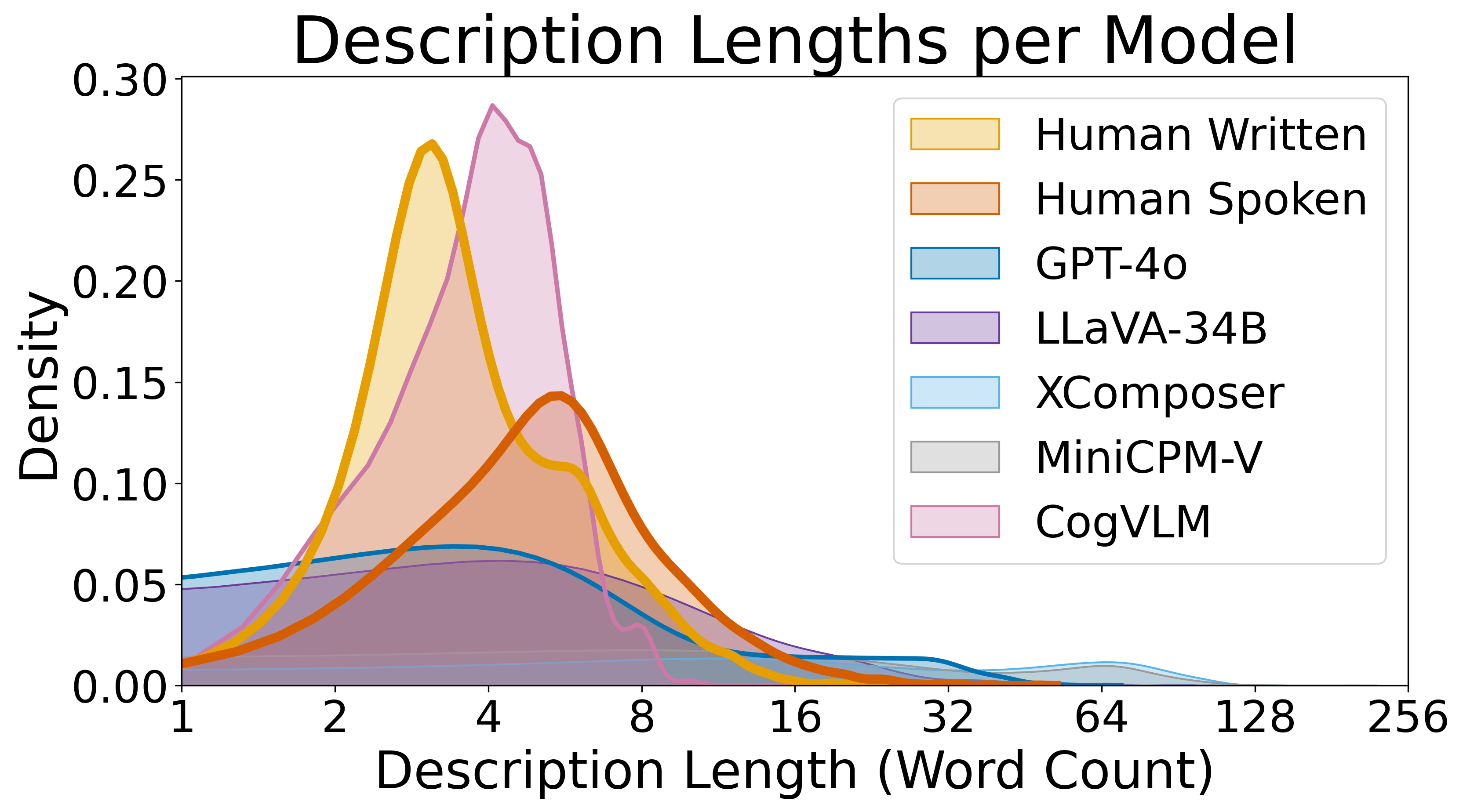
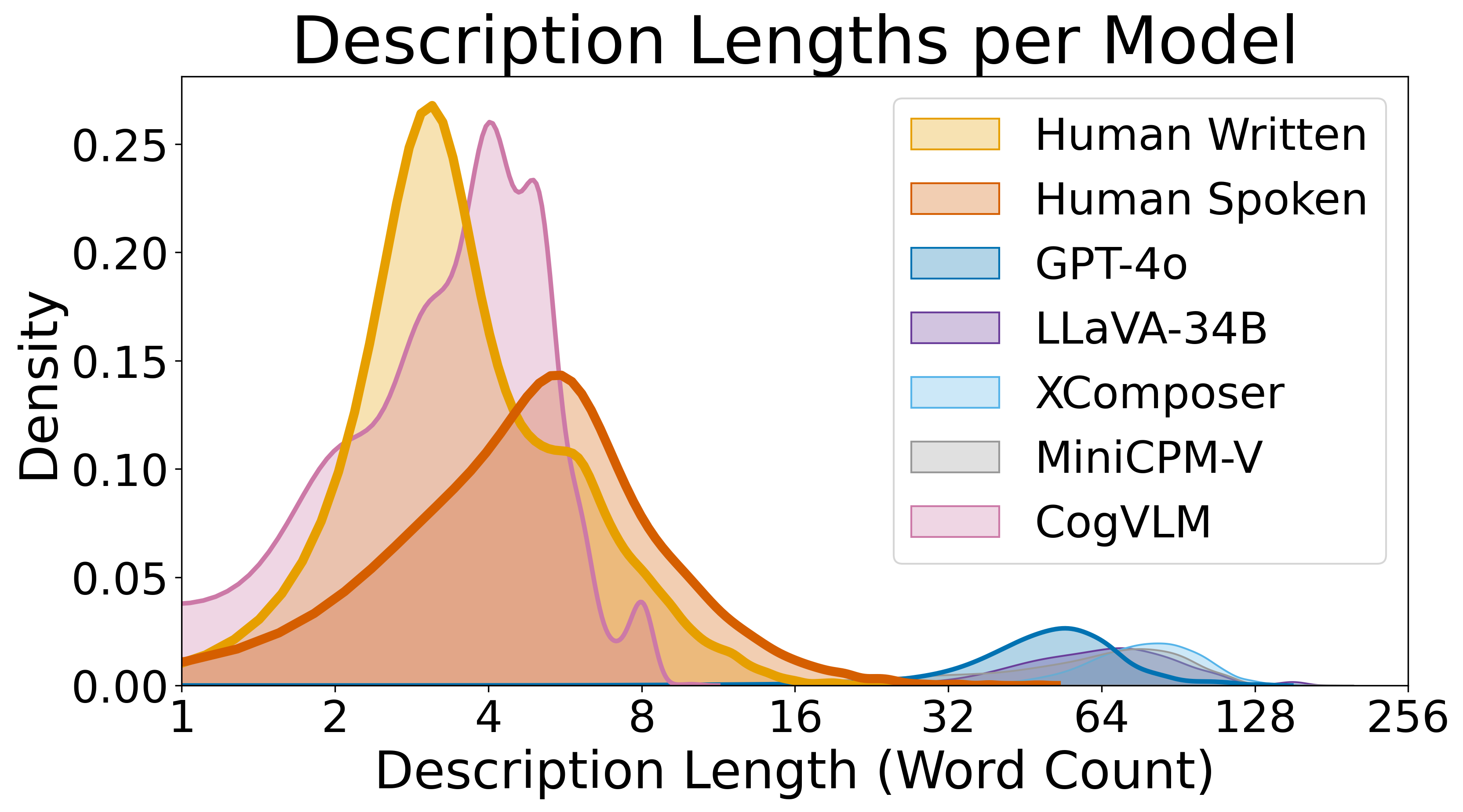
As shown in the tables, both reasoning-oriented prompts enhance performance in human evaluations. However,
most automatic metrics fail to reflect this improvement, which echoes our earlier critique that such metrics
overlook pragmatic quality. Furthermore, a notable trade-off emerges: while referential success improves, the
expressions become more verbose, as reflected by a higher proportion of irrelevant words. These findings
suggest that although prompting helps to some extent, it is insufficient to resolve the models' underlying
pragmatic limitations. Achieving human-like performance requires that pragmatic competence be instilled during
training as an intrinsic capability, rather than relying solely on prompt engineering.
Why Is Current Automatic Evaluation Unreliable?
Standard metrics such as BLEU, METEOR, and even model-based metrics like CLIPScore fail to capture key
pragmatic aspects. For instance, overly brief yet sufficient expressions (e.g., "cookie") are penalized by
BLEU, and paraphrased spatial constructions are unfairly punished by METEOR's fragmentation penalty.
Model-based similarity metrics also blur pragmatic distinctions. For example, "largest cookie" and "cookie"
may score similarly under CLIPScore despite large differences in informativeness. Listener-based metrics
further compound the issue by reinforcing biases toward salient objects.
These issues highlight the urgent need for pragmatically aware evaluation frameworks that
reflect human-like judgments.
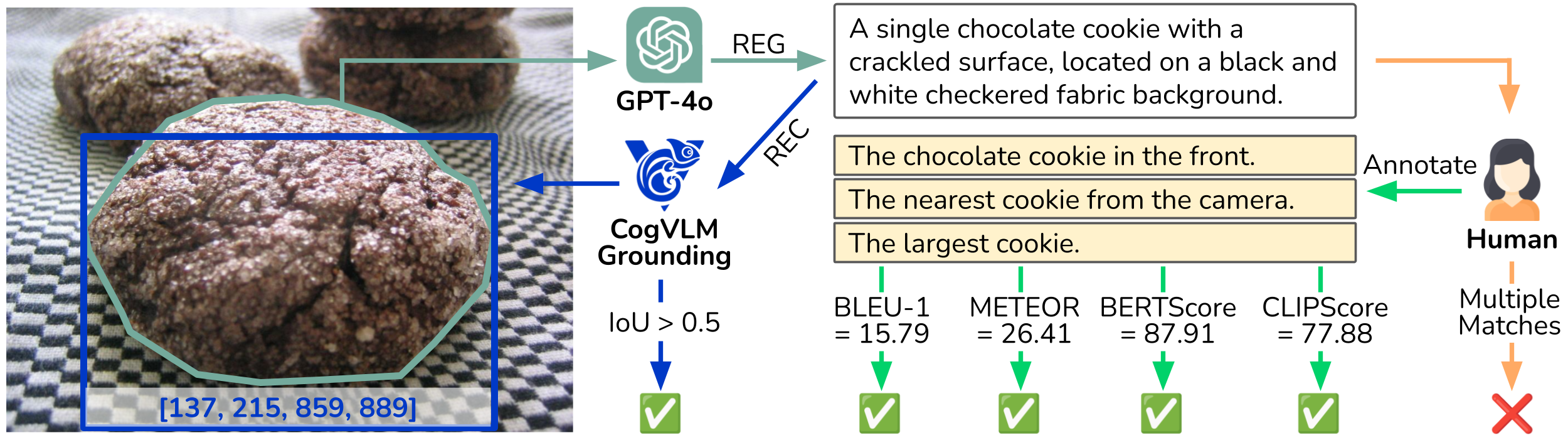
A case study illustrating why automatic metrics, including heuristic measures and neural listener models,
fail to accurately capture the pragmatic performance of REG.
Recommended Use of Our Dataset
The RefOI dataset is designed for fine-grained REG/REC analysis. It distinguishes between
COCO and non-COCO classes, and between scenes with single vs. multiple
distractors of the same class.
We encourage users to leverage these distinctions for deeper insights and invite community contributions to
expand non-COCO annotations.